近頃ネット社会では「クラウド」とか「ビッグデータ」なる言葉が流行っている。そこでここでは「クラウド」上の「ビッグデータ」の処理について考察する。ただし「クラウド」とか「ビッグデータ」なる言葉はバズワードと化しているので、定義をはっきりさせる必要がある。
一般に「クラウド」と言えば、インターネット上の信頼できる企業にデータの保存や管理を任せることを意味するが、ここではもっと一般的にインターネット上にあるサーバとして定義する。このように定義するのは、将来普及するかも知れないグリッドコンピューティングを念頭に置いているからであって、その場合には個人あるいは小さな組織もコンピューティグバワーやデータをインターネット上に提供していくことになる。
「ビッグデータ」も盛んに使われる言葉であるが、一般に既存のデータベース管理ソフトでは扱えないほどの巨大なデータを指しており、サイズはテラバイトクラスに昇る。幾つかのネット企業ではユーザの動向を逐一記録し販売促進に活用している。またネット上には膨大な情報が公開されている。そうした情報もマーケッティングに利用可能である。そうして蓄積された情報は膨大になりすぎて、管理の方法や利用のためのツールを見直す必要に迫られているのである。
Web は現在のインターネット社会において最も重要な役割を果たしている情報共有の技術である。テラバイトクラスを想定する「ビッグデータ」に対して、Web のサーバが扱うデータは遥かに小さい。そのサイズはせいぜいメガバイトクラスである。Web ではクライアントの求めに応じてデータをクライアントに送信する。データ転送に要する時間は回線の能力とデータサイズに依存する。そのため、ユーザの忍耐力を超えるような大きなデータを扱うわけにはいかないのである。
ではサーバのデータがメガバイトクラスを超え、ギガバイトクラスになると何が問題になるか? ここではこの問題に焦点を当てる。
データサイズがギガバイトクラスになるとデータをインターネット回線を通して転送するのに適さなくなる。他方、データサイズに比べるとプログラムのサイズは遥かに小さい。データを処理するのに必要なプログラムのサイズはせいぜい数メガバイトである。従って、プログラムをサーバ側に送信して、サーバ側でデータを処理し、処理結果を受け取る方が速い。
このように Web の実用限界との関係で語られるデータサイズを何と言えば良いのだろうか? 筆者の知る限り、この問題に関しては広く知られた用語は存在しない。「ビッグデータ」を既存技術が適用できないほどの巨大なデータであると定義すれば、情報共有技術である Web の技術が使えないギガバイトクラスのデータも「ビッグデータ」の仲間であると考えることもできる。しかし以下では混乱を避けるために、インターネット回線を通じて転送するのに適さないデータを「大きなデータ」と言うこととする。言うまでもなく、いわゆる「ビッグデータ」は「大きなデータ」である。
「大きなデータ」はインターネット回線を通じて転送するのに適さないのでサーバ上で処理される。処理に必要なプログラムはクライアントがサーバにアップロードすることになる。「大きなデータ」を多数の人々の間で共有し、それをサーバ上で処理するとなればセキュリティが大問題となる。従って以下では、セキュリティ問題に話を限定し、安全にサーバを運用し、かつクライアント側のニーズとセキュリティを確保するための方策に議論の焦点を当てることにする。
ここではクライアントのプログラムを、遠く離れているサーバ上で実行することをリモート実行と言うことにする。この意味でのリモート実行の歴史はインターネット胎動期(1970年前後)に現れた telnet と FTP から始まる。サーバの利用者はサーバ上に利用者の個人スペース(ホームディレクトリ)を与えられ、アクセスに必要なパスワードを知らされる。このスタイルは現在でも変わらない。
現在では個人所有のコンピュータ、いわゆるパーソナルコンピュータが普及し、大抵のことはパーソナルコンピュータで処理できる。そのためにリモート実行のニーズが少なくなっている。ホームページを運用している場合には保守のためにリモート実行が要求されることがあるが、それ以外の場合には高性能なコンピュータを使った特殊な計算を行いたい場合と、サーバにしかない大きなデータにアクセスしたい場合に限られるだろう。いずれも現在では普通の人々にとっては縁のない世界である。
しかし、将来はどうでであろうか? 科学の発展にとって収集したデータは可能な限り公開すべきである。生に近いデータが公開されていれば多様な視点からの分析が可能になる。視点が異なれば予想していなかったような発見があるかも知れない。現在は残念ながら特定の視点からの調理済みのデータしか公開されない。公開を Web で行っている限り、そのようになる。また、IT 化された社会の中では自動収集された膨大なデータが蓄積される。そのようなデータが適切に公開されていけば、社会にとって有用な情報が得られる可能性がある。分析視点の多様性を重視するならば、分析者のプログラムをサーバ側で実行できる必要がある。
現在、サーバの利用者はサーバ上に利用者の個人スペース(ホームディレクトリ)を必ず与えられる。なぜ与えられるのか?
マイクロプロセッサが現れる前の時代には、コンピュータと言えば大きく高価で、個人が独占的に使用できるような装置ではなく、共同で利用せざるをえなかった。当時のコンピュータはホストとも呼ばれていた。利用者は端末と呼ばれる装置を使ってホストを利用していた。端末の処理能力は不十分で、利用者が打ち込んだ命令をホストに伝えるだけであった。そのために、ホストには利用者ごとの記憶スペースが割り当てられ、利用者は端末を通じてホスト側にプログラムを作成し、ホスト側でプログラムを実行する他はなかった。
マイクロプロセッサが現れて、個人が独占的に使用できるコンピュータが出現した。それらはワークステーションと呼ばれ、その上でプログラムを作成し実行することが可能となった。高い処理能力が必要な場合には共同利用のホストが使えた。ホストにはこれまで通りに利用者の個人スペースが与えられた。プログラムを編集し保存するためと、FTP によるファイルの受け皿として、ユーザごとのスペース(ディレクトリ=フォルダ)が必要であると信じられてきた。この状況は現在でも変わらない。
リモートマウントはサーバのファイルシステムをクライアントのファイルシステムの一部であるかのように見せる技術である。この技術を使えば、サーバへのファイル転送のために FTP は不要になる。FTP でやっていたことは OS 付属のコピーコマンドでやっていけるのである。
リモートマウントのメリットは、普通のユーザにとっては
図6はプログラムが完成するまでの流れを FTP と比較している。マウント方式の方が手間が省けていることに注意する。
ネット上にはマウントはレイテンシ(遅延時間)が大きすぎて LAN レベルでしか実用にならないと述べている記事がいくつか存在する。インターネットでのマウントレイテンシは原理的な問題が絡んで改善しにくいと言う[1,2]。その根拠は、光の伝達速度が有限であり(光ファイバーの中での光の伝達速度は、真空中の光速の2/3程度である)、マウントのプロセスでは RPC(Remote Procedure Call) の技術が使われているために、マウントが完了するまでにサーバとクライアントの間で多数のメッセージのやり取りが発生する。そのために地球規模での WAN でのマウントでは時間が掛かりすぎて実用にならないと言う。こうした議論はいずれも LAN 環境を前提にして設計された NFS や CIFS を話題に採り上げている。また記事が作成された時期も古い。現在では実際にどの程度のものか? Plan9 の例を紹介する1。
まずマウントレイテンシの定義であるが、ネットの議論にはリモートマウントされたファイルの転送速度との混同があるように思えるのではっきりさせておく。ここではマウントの開始要求からマウントが完了するまでの時間を問題にする。具体的には time コマンドを使って
time マウントコマンド
紹介するのは筆者の自宅から Bell Labs のサーバをマウントする時のレイテンシである。日本からアメリカまでの距離でのレイテンシの目安になるであろう。測定してみると、レイテンシには結構なばらつきがある。ネットワークの混み具合も関係するが、2回目以降のマウントの場合にはクライアントのキャッシングによってレイテンシが大幅に短縮される。欲しいデータはキャッシングの影響を排除した時間である。そのためにはクライアントを立ち上げた直後に測定することになる。そうして得られた筆者の環境でのレイテンシは殆どの場合1秒台であるが、時には数秒かかることもある。なお筆者の自宅はインターネットと 1Gbps の光回線で繋がっている。実験に使用したクライアントは WiFi(802.11n) を使って家庭内 LAN と繋がっているのでバンド幅は1/2程度に小さくなるのであるが、結果には大きな影響はないであろう。インターネット回線における実効的なバンド幅はさらに小さいだろうから。
Plan9 では生まれた当初(1992年)から、Bell Labs のファイルシステムをローカル側にマウントすることによってソースプログラムの更新を行っている。他の OS の場合は全体をダウンロードして初めて更新の内容が分かるのであるが、マウント方式だと、改訂されたファイルの一覧を基にして必要なファイルのみをコピーすれば済む。ネットワークのバンド幅がまだ大きくない時代においてもマウント方式は実用的に使われていたのである。
マウントに必要な RPC の回数やマウントによるファイルコピーの速度は分散ファイルシステムの設計に強く依存する。ここに述べたのは Plan9 によるマウントで他のシステムの参考にはならないであろう。例えば文献[3]には sshfs が非常に遅いという苦情がある。残念ながら Plan9 以外でのマウントレイテンシの実測値が手に入らない。
マウントレイテンシに関する誤解の一つに、ファイルブラウザに表示されるまでの時間との混同がある。マウント要求を出してファイルブラウザにファイルの一覧が表示されるまでの時間は、マウントされるのに要する時間と、ファイルブラウザの表示に要する時間との和である。後者はファイルブラウザの設計と深く関わっている。図7のようにファイルブラウザがファイルの内容を表示している場合には、要する時間は、フォルダーの中のファイル数、ファイルの総サイズ、ネットワークの実効速度が関わっている。そのために、大抵の場合には LAN の中でしか実用にならないであろう。ここでは Mac の例を挙げたが Windows でも同様である。
[1] EETimes: File Sharing on the WAN: A Matter of Latency
http://www.eetimes.com/document.asp?doc_id=1272058 (2004)
[2] acmqueue: Bound by the Speed of Light
http://queue.acm.org/detail.cfm?id=1900007 (2010)
[3] Super User: faster way to mount a remote file system than sshfs?
http://superuser.com/questions/344255/faster-way-to-mount-a-remote-file-system-than-sshfs (2011)
[4] Plan 9 — Programmer's Manual (Volume 1)
http://plan9.bell-labs.com/sys/man/
http://plan9.bell-labs.com/sys/man/vol1.pdf
[5] Plan 9 — The Documents (Volume 2)
http://plan9.bell-labs.com/sys/doc/
クライアントやサーバにネットワークを通じてファイルシステムを提供しているのが分散ファイルシステム(Distributed File System)1である。ここにはリモートマウントの仕組みが使われている(図8)。
分散ファイルシステムは大学などの LAN 環境では既に古くから整備されている。これによって、学生用のパソコン教室では、どのコンピュータを使っても学生はサーバに保存されている自分のファイルにアクセスできるのである。
表1に示すように、いろいろな分散ファイルシステムが存在し、OS 依存性が強い。(強かった)
| server | client | 名称 | 製作者 | 適用範囲 | 公表年度 | 参考 |
|---|---|---|---|---|---|---|
| Unix | Unix | NFS (Network File System) ver.2 | Sun Microsystem | LAN | 1984 | |
| Unix | Unix | NFS (Network File System) ver.4 | IETF | LAN/WAN | 2003 | |
| Unix | Win | Samba | Open Source | LAN | 1992 | 注2 |
| Win | Win | DFS (Distribute File System) | Microsoft | LAN/WAN | 2008 | |
| Win | Win | CIFS (Common Internet File System) | Microsoft | LAN/WAN? | 1996 | 注3 |
| Win | Unix | Windows NFS Client | Microsoft | LAN | 1999 |
この表で「Win」とは Windows のことである。また「WAN」とはインターネット環境を指す。LAN を VPN(Virtual Private Network) で結んだネットワークは、管理面から見て LAN の一種だと考える。この表からは多くのものが省かれている。例えば分散 OS である Plan9 は生まれた時から高性能な分散ファイルシステムを備えていた。また最近の Unix 系の分散ファイルシステムは FUSE をベースにしているが、それらも表から省かれている。
[6] Wikipedia: Network File System
https://en.wikipedia.org/wiki/Network_File_System (参照 2016)
[7] デジタルアドバンテージ: ファイル共有プロトコル、SMBとCIFSの違いを正しく理解できていますか?(前編)
http://www.atmarkit.co.jp/ait/articles/1501/19/news092.html (2015)
[8] デジタルアドバンテージ: ファイル共有プロトコルSMB/CIFS(その1) (1/3)
http://www.atmarkit.co.jp/ait/articles/0410/29/news103.html (2004)
[9] Rem system: Windowsを利用していてWAN越しのファイル共有が遅い場合の検討事項
http://www.rem-system.com/post-304/ (2013)
[10] Wikipedia: Server Message Block
https://en.wikipedia.org/wiki/Server_Message_Block (参照 2016)
[11] Wikipedia: Samba (software)
https://en.wikipedia.org/wiki/Samba_(software) (参照 2016)
[12] Wikipedia: Windows Services for UNIX
https://en.wikipedia.org/wiki/Windows_Services_for_UNIX (参照 2016)
現在、ファイルシステムの OS 依存性を弱めるための新しい技術(FUSE)が注目されている。そして Ceph、 Gfarm、GlusterFS など最近の分散ファイルシステムの設計は FUSE ベースになっている[13]。さらに、既存のファイルシステムも FUSE ベースで再設計する動きがある[14]。
FUSE(Filesystem in Userspace) とは、ファイルシステムのプログラムコードをカーネルの外に置く技術である。カーネルには FUSE を実現するための汎用の小さなコードが含まれている必要がある。最近では主要な OS で FUSE がサポートされている。(アイデア自体は1990年前後に発表された Mach や Plan9 に由来する)
ファイルシステムがカーネルと固く結び付いていると、ファイルシステムの開発自体が困難であるばかりか、新しいファイルシステムの導入が OS 提供者に限定され、ユーザニーズが反映され難くなる。また分散ファイルシステムを構築する場合には OS を統一しなくてはならなくなる。FUSE によって、このような制約から解放される。
FUSE を応用したファイルシステムは多数ある。FUSE ベースの分散ファイルシステムはグリッドコンピューティングとの関係で注目されており、いくつか開発されている。その中でも Gfarm[15,16] は国際的にも高い評価を受けている分散ファイルシステムである。Gfarm は日本発の技術であり、ホームディレクトリを自動マウントできるように工夫されている[17]。
個人が手軽に使える FUSE ベースのファイルシステムとして sshfs が注目されている。これまでの Unix 系の分散ファイルシステムに比べて
[13] Wikipedia: List of file systems
https://en.wikipedia.org/wiki/List_of_file_systems (参照 2016)
[14] Ubuntu: FuseSmb
https://help.ubuntu.com/community/FuseSmb (参照 2016)
[15] 産総研: 世界中のストレージを統合するグリッド基本ソフトウェア「Gfarm」を無償公開
http://www.aist.go.jp/aist_j/press_release/pr2003/pr20031125/pr20031125.html (2003)
[16] oss-Tsukuba: つくばOSS技術支援センター: Gfarmファイルシステム
http://oss-tsukuba.org/software/gfarm (参照 2016)
[17] oss-Tsukuba: Gfarmファイルシステムをautomountする
http://oss-tsukuba.org/tech/automount (2013)
分散ファイルシステムにおける通常のマウントは、サーバ側のファイルシステムをクライアント側のファイルシステムにマウントするのであるが、それに対して、Plan9 では逆向きマウントが実現している。つまりクライアントのファイルシステムをサーバ側にマウントする。
逆向きマウントをサポートしているサーバ側の OS は(現在のところ) Plan9 だけである。クライアント側は Plan9 の他、Unix、Linux、Mac、Windows などでサポートされている。
逆向きマウントだけでは意味がないので、実際にはクライアントのリモート実行コマンドと組になっている。リモート実行コマンドを実行すると、同時に自動的にクライアントのファイルシステムがサーバ側にマウントされるのである1。リモート実行コマンドとしては Plan9 端末(Plan9 クライアント)では cpu、Plan9 以外のクライアントでは drawterm を使う[18,19]。
正方向のマウント(サーバのファイルをクライアントに見せるマウント)の場合には、クライアントのプログラムをサーバで実行するプロセスは次のようになるであろう。
ssh コマンドでリモートログインするcpu コマンドでリモートログインする
[18] Russ Cox: Drawterm
https://swtch.com/drawterm/
[19] Cinap Lenrek: DRAWTERM
http://drawterm.9front.org/
ここではデータの提供とデータ処理のための CPU パワーを提供するサーバについて考えて見る。以下、これをデータサーバと言う。データサーバにはどのような特性が求められているのだろうか?
データを還元処理によって得られたものが情報である1。極端には1ビットにまで還元される。還元処理は問題意識(目的)に依存し、大きなデータではさらに技術が求められる(図10)。
記録メディアの価格が低下し続けた結果、最近では膨大なデータを保持するようになった。データ収集時にデータを厳選するよりも、集められるデータは片っ端から集め、後で整理するやり方が可能になっているのである。そこで、我々はデータに対して次の見方を採ることができる。
情報の抽出は一意的ではない。多様な問題意識が存在し、そこから多様な情報が生まれる。分析する視点が異なれば、意外な結論も得られるのである。従ってデータを公開し、多様な目で検討できるようにすることが重要である2。
データが小さい場合には既存技術でもやっていける。サーバからユーザがダウンロードすればよい。しかし、大きい場合には...
Web ではサーバ運営者の問題意識にそって情報が抽出される。今はそれで我慢しているのである。
大きなデータの処理にはリモート実行を許す必要がある。つまり、データを移動させないで、サーバ上で直接処理する必要がある。その場合には
これらを行うために、現在の方式(Unix のリモート実行)ではユーザ登録の際にパスワードとホームディレクトリが与えられる。
しかし、データサーバにとって、利用者は一時的である。必要な結果が得られればアクセスするニーズがなくなるであろう。そうした利用者にホームディレクトリを与えるのは合理的ではない。サーバにそのためのディスクスペースが要求され、しかも必要な大きさは前もってはわからない。サーバ側としては十分な大きさのディスクスペースを提供するしかないであろう。
利用者が彼らのスペースに保存しているファイルは、一時的に必要とされ、使い終わったものなのかも知れないし、後々に必要とされる大切なものかも知れない。また他人には見られたくないものなのかも知れない。サーバの管理者には適切な管理義務が発生する。
ホームディレクトリは本当に必要なのだろうか? ホームディレクトリが必要とされる理由は、FTP などによるファイル転送の際にファイルの受け皿が必要と考えられるからである1。しかし図9について考えてみよう。クライアントのプログラムをサーバ側で実行するにあたって、Plan9 の場合には、実はホームディレクトリは大した役割を果たしていないのである。
サーバの管理者にとってグリッドユーザは特殊な存在である。ボランティア的にサーピスを提供しているにすぎない相手である。しかも顔が見えない相手である。彼らに対して貴重な記憶装置を特別に準備するのは抵抗があるだろう。ユーザのデータはユーザが所有する記憶装置に保管するのが管理者側とユーザの双方の利益である。そこで図11に示すサーバ側の要求は実現可能か否かを考える。
具体的には次の要求仕様を考えてみる。
サーバ側の要求は厳しい。
この実現には Plan9 の逆方向マウントを利用すれば可能である。逆向きマウントによってサーバ上で直接クライアントのプログラムを参照できる。ただし Plan9 自体はホームディレクトリの存在を想定しているので、多少の手直しが要求される。特にセキュリティ上の理由からカーネルのパッチが要求される。 この仕様は、実際に筆者のグリッドサーバ1で実現されている[20]。
ホームレスデータサーバの場合には、クライアントとサーバとの関係は図12のようになる。
この図は図9と似ているがホームディレクトリが存在しない。工夫すればホームディレクトリ無しにやっていけるのである。
筆者のサーバはグリッドコンピューティング用に設計されている。そのために認証はマルチドメイン認証に対応している。しかも、認証の対象となるサーバの所属ドメインがマルチであるばかりではなく、認証チケットを発行するドメインもマルチである。現在は Bell Labs のチケットあるいは筆者が独自に発行するチケットで利用可能になっている。
さらにグリッドサーバを踏み台とした不正アクセスを防ぐために、サーバからのネットワークアクセスを防止している2。
[20] Kenji Arisawa: A New Grid Server
http://p9.nyx.link/9grid2/9grid.html (2015)
次の実行例は Plan9 のユーザを想定している。彼らの多くは Bell Labs のアカウントを持っている。そこで、このアカウントの保有者に対してサーバへのアクセスを許可するようにサーバが設定されている。サーバにログインするためには、Plan9 の認証エージェント factotum に対して次の認証キーを登録しておく。
key dom=outside.plan9.bell-labs.com proto=p9sk1 user=XXXXX !password=YYYYY
XXXXX は Bell Labs のアカウント名であり、YYYYY は Bell Labs でのパスワードである。ドメイン名が指定されていることに注意する。このサーバはマルチドメイン認証に対応しており、サーバ側は他のドメインのユーザも受け付ける。
サーバにログインするには cpu コマンドを使う。
cpu -h grid.nyx.link -k 'dom=outside.plan9.bell-labs.com'
grid.nyx.link は筆者のサーバであり、outside.plan9.bell-labs.com のアカウントを使うことを指定している。一般的に言えば factotum には複数の認証キーが登録されているので、その内のどれを使うかを指示しているのである。ログインに成功すれば “grid%” のプロンプトが表示される。
まず最初に ps コマンドを実行してみるとよい。
grid% ps arisawa 1 0:00 0:00 256K Await bootrc arisawa 2 0:00 0:00 0K Wakeme mouse ... none 369 0:00 0:00 132K Open listen none 370 0:00 0:00 132K Open listen arisawa@outside.plan9.bell- 20188 0:00 0:00 124K Await gcpu arisawa@outside.plan9.bell- 20195 0:00 0:00 240K Await rc arisawa@outside.plan9.bell- 20196 0:00 0:00 124K Pread gcpu arisawa@outside.plan9.bell- 20247 0:00 0:00 116K Pread ramfs arisawa@outside.plan9.bell- 20252 0:00 0:00 92K Pread ps grid%Bell Labs のアカウントでログインした場合にはプロセスのオーナは
XXXXX@outside.plan9.bell-labs.com となっている。多様なドメインのユーザの利用を許し、プロセスが干渉しない保障を得るためには、このようにプロセスのオーナ名にドメイン名を含めざるを得ないであろう。なお、ps の表示が bell- で切られているのは、単に表示幅の節約のためである。
次に
ls /usr
/usr/none と /usr/arisawa の他に、クライアント側のユーザの一覧が見えるはずである。例えばクライアントのユーザ名が bob であれば、/usr/bob が見える。もちろん /usr/bob の下にあるデイレクトリやファイルはクライアントのものである。bob はそれらを使って、自由に自分のプログラムを実行できる。
もしも bob の他に carol もログインしていたらどうなるか? Plan9 と Unix との大きな違いの一つにユーザが見る名前空間の根本的な違いがある。Plan9 においては異なるユーザは異なる名前空間に属している。その結果、carol は /usr/bob を見ることはないし、逆もまた然りである。
最後に Plan9 のテキストエディタ acme を実行してみる。このエディタはマウスを使え、そしてファイルブラウザを兼ねているのでサーバの様子をざっと見るのに良いであろう。もちろんファイルの編集もできるが、編集はローカル側で行った方がレスポンスが良い。
筆者のサーバではシステム領域や他ユーザの領域への書き込みは禁止されている。書き込みはクライアント側にあるユーザの領域と、ユーザの便宜のために準備された ramfs にのみ許される。ramfs とはメモリーの中のファイルシステムであり、Plan9 ではユーザごとに割り当てられる。ramfs は、ログインで生成され、ログアウトで消滅する。/tmp は ramfs で実装されている。どのユーザも /tmp である。/tmp も Plan9 の私的な名前空間の中にあり、他のユーザと干渉し合うことはない。またクライアントのファイルシステムは /mnt にマウントされるが、他のクライアントとは別の名前空間にあるために干渉し合うことはない。
グリッドユーザが見る名前空間は、システムユーザが見る名前空間の一部である。Unix ではファイルの保護は許可ビットで与えるが、Plan9 ではその他にカプセル化によって隠蔽できる。例えばシステムユーザの個人的なファイルの他、/sys/log、/mail などがグリッドユーザには隠蔽されている。
世間一般の認識では世界規模の WAN レベルのマウントは遅くて実用になるはずがないと言うことらしい。このような認識は著名な雑誌のレフリーですら持っている1。彼らは Unix や Windows の常識で考えている。しかし Plan9 のマウントは速い。既に述べたように、日本からアメリカ (Bell Labs) までのマウントレイテンシは数秒である。マウント後に続くユーザの作業時間を考えた時には、この時間は完全に無視できるだろう。
ではホームレスデータサーバのレイテンシはどうか? 具体的には
time cpu -h grid.nyx.link -k 'dom=outside.plan9.bell-labs.com' -c pwd
pwd を実行するのに必要な時間の測定である。
認証サーバとしては Bell Labs のものが使われているので、cpu コマンドの実行によってログインするまでには次の3ステップが内部で実行される2。
幸いシアトルに住む友人が実験に協力してくれた。報告によれば3回の実験で結果は各々 7.58秒、7.22秒、8.17秒である。この値は Plan9 による日本からアメリカまでのマウントレイテンシの数倍である。cpu コマンドが完了するまでのサーバとの交信回数は通常のマウントに比べて数倍に昇るので、妥当な数値であろう3。この数値が大き過ぎて実用にならないのか否かは行われる内容に依存するが、殆どの場合には問題にはならないであろう。
cpu コマンドによるリモートアクセスの技術
筆者のサーバではユーザを次のように分類している。
none
グリッドユーザにはホームディレクトリを与えない。筆者はグリッドユーザとして Bell Labs に登録されたユーザを想定している。従って、ここに登録されたユーザは筆者のサーバを使えるように設定している。ところが筆者は Bell Labs にユーザ登録されたユーザのリストは持っていないのである。従ってホームディレクトリは与えようがない。筆者のグリッドユーザを Bell Labs のユーザに完全に限定してしまえば、ユーザ登録に関する一切の作業は必要がなくなり、またグリッドユーザは利用にあたって筆者と連絡をとる必要もない。
Plan9 ではシステムユーザは本来ならネットワークが許されている。しかし、このシステムではグリッドユーザの巻き添えを食ってシステムユーザもネットワークができないようになっている。このサーバは家庭内の LAN の中に置かれているために、セキュリティの関係でネットワークは困るのである。ネットワークの禁止は完全を期してカーネルレベルで行っている。Plan9 のカーネルは、ユーザを3つに分類している。ホストオーナと none とその他である。そのためにグリッドユーザとシステムユーザの区別ができないのである。
Plan9 のホストオーナは Unix の root に相当する。Unix と異なりホストオーナに固定した名前はない。マシンを立ち上げたユーザがホストオーナになるのである。
ユーザ none は Unix の nobody に相当し、主にネットワークサービスを受け持っている。Unix では nobody の他にも、八百万の神様(デモン)を持っているが、Plan9 では none 一個で済ませている。
Plan9では名前空間をカプセル化できる。Unix でもある程度はできるが実用の域には達していない。筆者のグリッドサーバは筆者が普段使っているファイルサーバの下で動いている。従って私的なファイルも存在し、グリッドユーザからは、そうしたファイルの存在自体を隠したいのである。そのために Plan9 の名前空間のカプセル化が利用されている。
以上の説明をまとめると次の表のようになる。
| ユーザ | ネットワーク | 名前空間 | ホームディレクトリ | 仕事 |
|---|---|---|---|---|
| グリッドユーザ | 不可 | 限定する | 無 | |
| システムユーザ | 不可 | 限定せず | 有 | |
| ホストオーナ | 可 | 限定せず | 有 | システムメンテナンス |
none |
可 | 限定せず | 有 | ネットワークサービス |
ホームレスサーバ自体は Plan9 の標準環境に多少の手を加えれば実現できる。次の2つのコマンドにわずかのパッチを当てれば済む。クライアント側は標準環境のままで構わない。
factotumcpu コマンド
しかし Plan9 は筆者のようなサーバの使い方を想定していないので、そこから発生するセキュリティ上の問題を解決しなくてはならない。例えば、本来の Plan9 では、どのユーザも none になれるとされている。しかしグリッドユーザも none になれるようであれば、表2に示した分類自体が意味をなさないのである。表2の通りに働くためにはカーネルのパッチ当てが必要になる。
筆者のサーバの場合以下のようなパッチが当てられている。
none になれる
none 以外は内部からのネットワークが防止されていると言う意味である。
筆者がホームレスサーバを考える動機になったのはグリッドコンピューティングである。グリッドコンピューティングが目指すパラダイムは次の図で上手に表現されている。

図を注意深く観察すると、小さな魚は実は PC ではなく、ワークステーション(PC より少し上位クラスのコンピュータ)である。グリッドコンピューティングを上手にこなすには、Unix ワークステーションクラスのコンピュータが必要と考えたのであろう。
この図に示す考えは、実は Google や Amazon など著名なネット企業がシステムを組む際に既に採用しており、クラスターコンピューティングとも呼ばれている。高価なスーパーコンピュータでシステムを組むよりも、安価な市販品を多数組み合わせてシステムを組む方が安く済むからである。さらに大規模なデータ処理はこの方が効率的で、また障害に対する耐久性が高い。
グリッドコンピューティングに結びつく考えは1990年代の初頭からすでに提唱され、研究機関で模索された。1990年代末に至るまでのグリッドコンピューティングの研究と将来への展望は、Ian Foster たちの本に詳しく纏められている[22]。研究機関へのグリッドコンピューティング普及の中心的な役割を担ったのは Globus[23] で、現在におけるグリッドコンピューティングのソフトウェア基盤を築き上げた。
データセンターにおけるクラスターコンピューティングに対する、研究機関を結ぶグリッドコンビューティングの難しさは、参加するコンピュータの多様性にある。データセンターの場合にはコンピュータは仕様を統一できる。しかし、研究機関を結びつけるグリッドネットワークでは管理主体が異なっているために仕様を統一するのは難しい。特別の努力が必要とされているのである1。
[21] Maya Haridasan: Cluster/Grid Computing
http://www.cs.cornell.edu/courses/cs614/2004sp/slides/Clusters4.ppt (2004)
[22] Ian Foster and Carl Kesselman:
The Grid: Blueprint for a New Computing Infrastructure
Morgan Kaufmann Publishers Inc. San Francisco, CA, USA ©1999
[23] Globus: Research data management simplified
https://www.globus.org/ (参照 2016)
[24] T2K筑波システムの概要と利用プログラム計画
http://www2.ccs.tsukuba.ac.jp/workshop/t2k-sympo2008/file/boku.pdf (2008)
[25] 合田憲人,他
高性能分散計算環境のための認証基盤の設計
Symposium on Advanced Computing System and Infrastructures
先進的計算基盤システムシンポジウム SACSIS2012 (2012)
http:IPSJ-SACSIS2012061.pdf
次の図14は Globus のホームページに載っている Gentzsch の論文[28]から借用している。Gentzsch は、データセンターの中で実現されているクラスターコンピューティング(Cluster Grid)と研究機関を結ぶグリッドコンピューティング(Global Grid)の間に、中間的な形態があると言う。分類の視点は、グリッドの運用人員(team)と運用組織(organization)である。
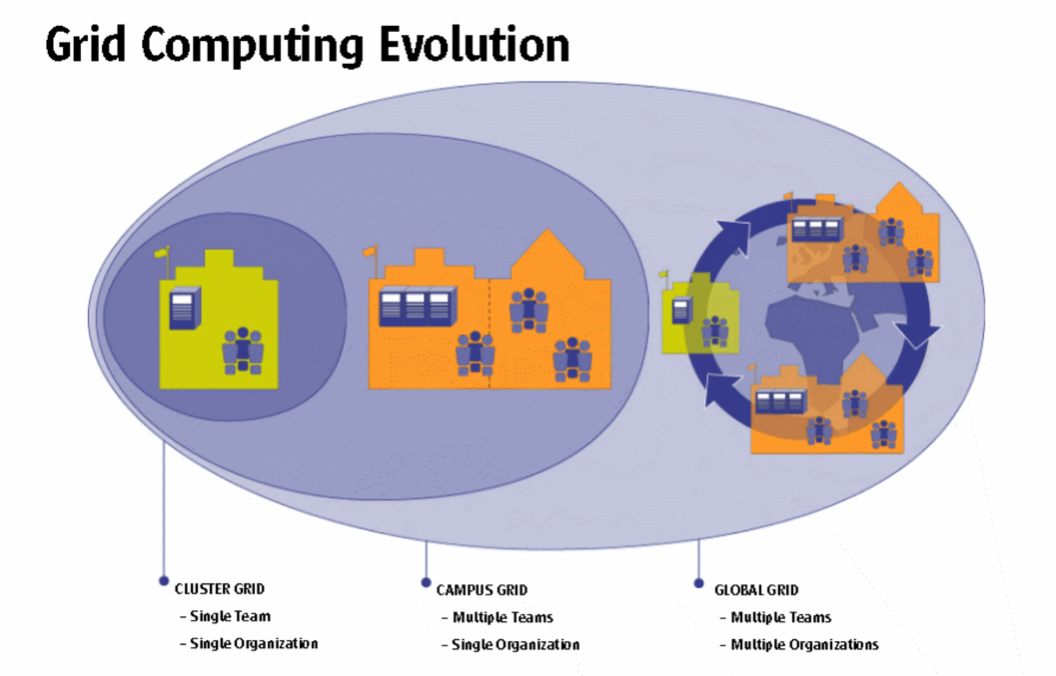
中間的な形態として図では “Campus Grid” となっている。しかし、この著者の図のキャプションでは “Enterprise” となっているのである。両者に共通しているのは、単一組織が運用している点である。この場合にはシステムを組むに当たって認証システムは1つに統一される。クラスターとの違いはどこにあるか? クラスターでは認証はもっとシンプルなはずてある。もちろんクラスターの外から中へのアクセスは認証が求められるはずであるが、クラスターの内部で行われているコンピュータ相互のアクセスでは認証は不要であろう。
図の “Global Grid” についても他の呼び方がある。例えば “Collaboration Grid” である[26]。 “Global Grid” はインターネットレベルのグリットであることが強調されているのに対して、"Collaboration Grid" はグリットを構成する組織が単一ではないことが強調されている。グリッドの難しさの本質は、グリッドの管理にあることを考え、ここでは “Collaboration Grid” を採用する。
そこで表3に筆者による分類をまとめる。ついでに筆者のホームレスグリッドサーバ(9grid)も表に組み込んでいる。
| 分類 | 認証システム | 分散ファイルシステム | 適用範囲 |
|---|---|---|---|
| Cluster | 不要 | 統一可能 | LINK1 |
| Campus/Enterprise | 必要(統一可能) | 統一可能 | LAN2 |
| Collaboration | 必要(統一困難) | 採用困難 → FTP | WAN |
| (9grid) | 必要(統一不要) | 不要 | WAN |
表の「分散ファイルシステム」の欄では、サーバとクライアント間で分散ファイルシステムが利用可能か否かを問題にしている。グリッドコンピューティングに利用可能な多数のサーバが一つの組織に属していれば、それらを分散ファイルシステムで結ぶのは現在では当たり前のことと考えてよい。Collaboration グリッドでは、分散ファイルシステムについて「採用困難」と書いたが、最新の技術である Gfarm を使うと実用のレベルに達しているかも知れない。しかし筆者は評価の手段を持たないし、性能を評価した文献も知らない。
factotum を通じて統一されている。
[26] Vassiliki Pouli, Yuri Demchenko, Constantinos Marinos, Diego R. Lopez, and Mary Grammatikou
Chapter 9: Composable Service Architecture for Grid (文献[27])
[27] Nikolaos P. Preve: Grid Computing
Toward a Global Interconnected Infrastructure (Springer, 2011)
[28] Wolfgang Gentzsch: Grid Computing Adoption in Research and Industry
http://toolkit.globus.org/ftppub/liming/GridCompfeb03.doc (2003)
9grid と呼ばれるグリッドは、今回の筆者のホームレスデータサーバの以前に、歴史上2度現れ異なるグリッドプロジェクトに対して使われている。最初に現れたのは Bell Labs と University of Calgary との共同研究プロジェクトのグリッドである[31]。この成果は文献[29]に纏められている。この内容はまた Mirtchovski の博士論文に詳しく解説されている[30]。これらの論文では、Plan9 はグリッドコンピューティンクに適した OS であると主張された。
彼らに刺激されて、メーリングリスト 9fans に集まる Plan9 ユーザがグリッドコンピューティングの実験を始めた。グリッドサーバがボランティア的に提供され、各自が各自のやり方でグリッドサーバを構成した。筆者もサーバを提供し、並列コンピューティングの実験を行い、そのソフトを公開している[32,33]。これが 9grid の第2期である。このユーザーズグループによって、標準配布の Plan9 に少し手を加えるだけでマルチドメイン認証が可能になることが見つけられた。彼らの実験の成果は Plan 9 Wiki に纏められている[31]。Wiki にはグリッドサーバに対する新しいアイデアも述べられている。しかしながら、それらのアイデアは実現されることもなく第2期は終息した。9fans に集まるユーザの関心はもっぱら技術的な問題にあり、その解決のメドが立った段階で関心を無くしたと思われる。
もしかすると何十年か先に 9fans によるこの時期の活動は別の視点から歴史家の評価を受けるようになるかも知れない。すなわち、研究所の高性能なコンピュータとネットワークの中で生まれ育まれたグッドコンピューティングが、Plan9 による新しい技術によって初めて研究所の外に踏み出し、普通のコンピュータと普通のネットワーク回線の中で実験されたと。
9grid の第3期になるか否かは不明だが、あれから10年、筆者は 9grid を再び考えてみることとした。グリッドサーバの必要用件からホームディレクトリを除去できるのではないかと考えたからである。ホームディレクトリをグリッドユーザに提供しなくてもよいのなら、グリッドサーバを気楽にユーザに提供出来るだろう。これをホームレスグリッドサーバとは言わないのは、グリッドサーバは複数個の存在を想定しているのであるが、ホームレスデーターサーバは今の所世界でただ一つしか存在しないからである。
[29] Andrey Mirtchovski, Rob Simmonds and Ron Minnich
Plan 9 – an Integrated Approach to Grid Computing
Parallel and Distributed Processing Symposium, 2004. Proceedings. 18th International
http://p9.nyx.link/9grid/plan9-grid.pdf (mirror)
[30] Andrey A. Mirtchovski
Grid Computing with Plan 9 – an Alternative Solution for Grid Computing
http://mirtchovski.com/p9/thesis.pdf (2005)
http:thesis.pdf (mirror)
[31] Plan 9 Wiki — 9grid
http://plan9.bell-labs.com/wiki/plan9/9grid/ (参照 2015)
http://p9.nyx.link/wiki/9grid/ (mirror)
http://9p.io/wiki/plan9/9grid/index.html (mirror)
[32] Kenji Arisawa: Plan 9 Grid Computing
http://p9.nyx.link/9grid/
[33] Kenji Arisawa: グリッドツールキット
http://p9.nyx.link/9grid/gtk.html (2005)
グリッドコンピューティングに関する2000年頃までの状況に関しては文献[35,36]に詳しいので、ここでは省略する。現在、研究機関でのグリッドコンピューティングは、研究の基本インフラとしてヨーロッパとアメリカで定着しているようである。
ヨーロッパでは 2002年から2004年の DataGrid プロジェクト[37]、2004年から2010年の EGEE(Enabling Grids for E-sciencE) プロジェクト[38]を経て、2010年からは EGI(European Grid Infrastructure) プロジェクト[39]に引き継がれている。ここには2016年現在、世界中から200以上の研究機関が参加している[40]。 アメリカでは早くも1988年から大学でのグリッドプロジェクトが動いており[45]、現在では OSG(Open Science Grid) が中心になってグリッドコンピューティングを進めている[46]。Wikipedia によると2009年現在42大学が OSG に参加しているという[47]。
EGI と OSG に基礎を置いて、世界最大のグリッド WLCG(Worldwide LHC Computing Grid) が組織されている。この組織を調整しているのは CERN であり、LHC(Large Hadron Collider) から生み出される巨大なデータを世界中の研究者の間で共有することを使命としている[44]。
ある雑誌の記事を次に紹介する。
「e-Science」という言葉をお聞きになったことがあるでしょうか。聞いたことのある方は「高度に分散化されたネットワーク環境で実施されるコンピュータを多用した科学などと言われ,主に自然科学の分野で,研究成果や研究過程で生み出される大量のデータを共有し,新たな研究への利活用を行おうとする取組み」等といった理解をされているかと思います。
一方で近年,大量のデータを共有,活用するというe-Scienceと似た取り組みが,あらゆる分野で盛んに行われつつあります。ビジネスの分野では「ビッグデータ」や「クラウドコンピューティング」と呼ばれるさまざまな技術やサービスが普及し,ログ等の大量の生データを解析し,ビジネスに活きる知見を引き出す「データサイエンティスト」という専門家が注目を集めつつあります。自然科学分野では「オープンサイエンス」,「ビッグサイエンス」,「eリサーチ」等と呼ばれる取り組みが進みつつあり,一方で人文科学分野ではDigital Humanitiesという分野が隆盛し,研究分野を超えた学際的な研究も盛んになりつつあります。
...
グリッドコンピューティングを支える理念は e-Science に示されている研究者間でのデータ共有であり、単に高速の計算環境を提供したいと言うことではないのである[35,42,47]。こうした欧米の動きに比べると日本は非常に遅れている1。
現在の Collaboration グリッドは研究機関のグリッドである。この分野はグリッドコンピューティングのニーズが高く、多数の高性能なコンピュータを集めやすい。また高速なネットワークが研究機関の間で整備されている。つまりグリッドコンピューティングが発展しやすい分野なのである。しかし、将来、世の中の IT 化がさらに進行した時にグリッドコンピューティングが研究機関の外に広がる可能性はどうだろうか? World Wide Web は CERN から始まり、研究機関に広がり、現在では世界中の人々にとってなくてはならない存在となっている。同様なプロセスを辿るのだろうか? 将来には家庭のあらゆるデバイスがインターネットと接続すると予想されている。そのコンセプトは「モノのインターネット(IoT)」と呼ばれている。そのような時代には研究所のスタイルではない新しいグリッドが求められる可能性が残されている。そこでは高性能なコンピュータや高性能なネットワークを求めることはできないし、またグリッドのために提供できる資源は限られてくる。さらに家庭内にサーバを設置するとなれば完全なセキュリティが求められるだろう。そしてグリッドユーザごとのホームディレクトリの提供はできそうもないだろう。筆者のホームレスデータサーバは、そうした未来を視野に置いた一つの提案である。
[34] Edited by Fran Berman, Geoffrey C. Fox and Anthony J. G. Hey
Grid Computing — Making the Global Infrastructure a Reality —
(John Wiley & Sons, 2003)
[35] Fran Berman, Geoffrey Fox and Tony Hey
The Grid: past, present, future
(ref.[34], pp.9-50)
[36] Ian Foster
The Grid: A new infrastructure for 21st century science
(ref.[34], pp.51-65)
[37] The DataGrid Project
http://eu-datagrid.web.cern.ch/eu-datagrid/ (参照 2016)
[38] EGEE: Welcome
http://eu-egee-org.web.cern.ch/eu-egee-org/ (参照 2016)
[39] EGI: HOME
http://www.egi.eu/ (参照 2016)
[40] EGI: Virtual organisations
http://www.egi.eu/community/vos/ (参照 2016)
[41] EGI: Wiki
https://wiki.egi.eu/wiki/Intranet/ (参照 2016)
[42] EGI: Weaving The Internet Of Data
http://www.egi.eu/blog/2016/03/21/weaving_the_internet_of_data.html (参照 2016)
[43] WLCG: Welcome to the Worldwide LHC Computing Grid
http://wlcg.web.cern.ch/ (参照 2016)
[44] WLCG: Welcome
http://wlcg-public.web.cern.ch/ (参照 2016)
[45] HTCondor: Computing with HTCondor
https://research.cs.wisc.edu/htcondor/ (参照 2016)
[46] Open Science Grid
http://www.opensciencegrid.org/ (参照 2016)
[47] Wikipedia: Open Science Grid Consortium
https://en.wikipedia.org/wiki/Open_Science_Grid_Consortium/ (参照 2016)
[48] 情報科学技術協会: 2013. 9 特集=e-Scienceとその周辺~現状とこれから~
http://www.infosta.or.jp/journals/201309-ja/ (2013)
[49] 学際大規模情報基盤共同利用・共同研究拠点
http://jhpcn-kyoten.itc.u-tokyo.ac.jp/ja/ (参照 2016)